MeDM enables temporally consistent video rendering and translation using image Diffusion Models. Slide for interactive comparison. Inputs are on the left.
Abstract
MeDM utilizes pre-trained image Diffusion Models for video-to-video translation with consistent temporal flow. The proposed framework can render videos from scene position information, such as a normal G-buffer, or perform text-guided editing on videos captured in real-world scenarios. We employ explicit optical flows to construct a practical coding that enforces physical constraints on generated frames and mediates independent frame-wise scores. By leveraging this coding, maintaining temporal consistency in the generated videos can be framed as an optimization problem with a closed-form solution. To ensure compatibility with Stable Diffusion, we also suggest a workaround for modifying observed-space scores in latent-space Diffusion Models. Notably, MeDM does not require fine-tuning or test-time optimization of the Diffusion Models.
We extract a 20-pixel-wide vertical segment of pixels from each generated frame and stack them horizontally. MeDM produces fluent videos which reconstruct stripe-free images. Show video.
Architecture
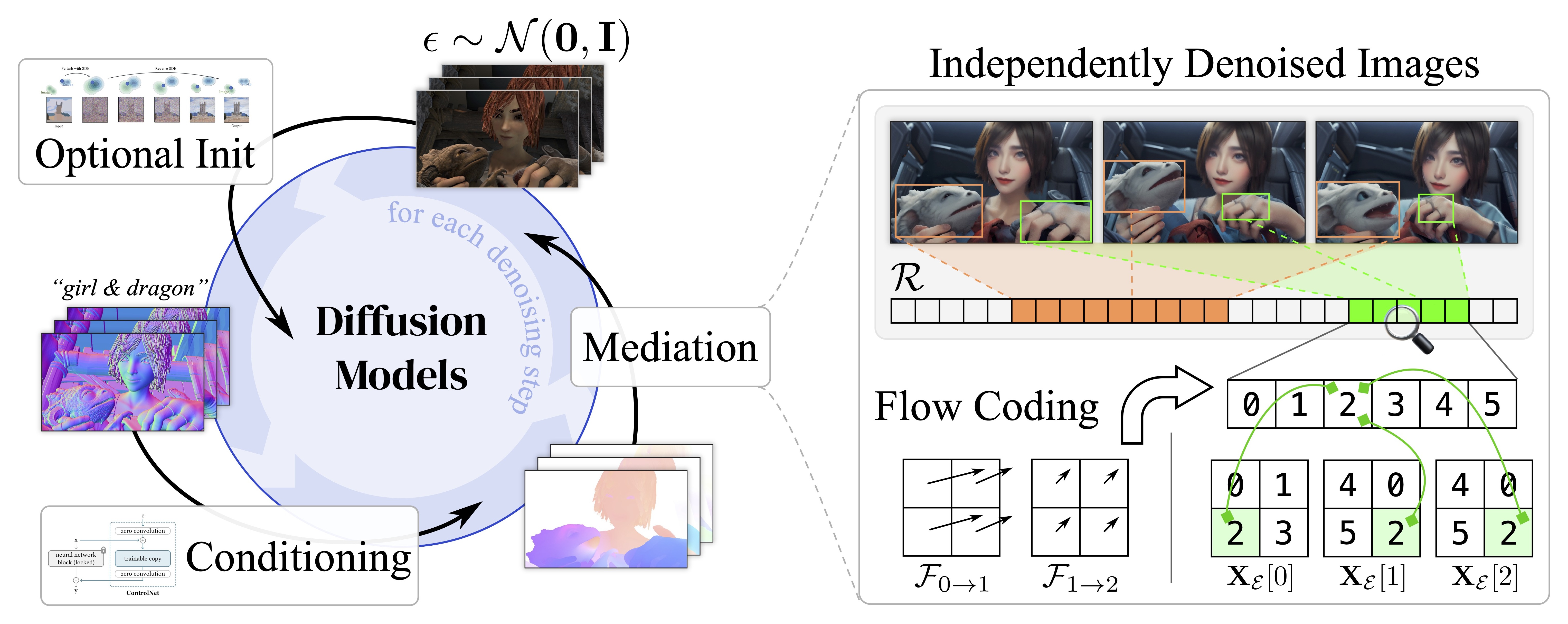
MeDM mediates independent image score estimations after every denoising step. Inspired by the fact that video pixels are essentially views to the underlying objects, we construct an explicit pixel repository to represent the underlying world. For more details, please refer to our paper.
Video Rendering
MeDM is capable of efficiently rendering high quality videos solely from 3D assets, including optical flows, occlusions and position information (depth, normal). We use the lineart derived from the normal maps as the input conditions to ControlNet. 3D assets from MPI Sintel.
Loading gallery...
In addition, MeDM can also begin with adding noise to the pre-rendered videos and perform the denoising process from 0.5T step following SDEdit. The generated video should be similar to the original animation and incorporating the realistic prior from the pre-trained DM (The difference is especially significant in complex texture, such as hair). More quantitative results, including comparison with prior works, can be found in our paper.
Loading gallery...
Text-Guided Video Edit
MeDM also performs well without high precision optical flows. We demonstrate this by applying text-guided video editing on real-world videos in DAVIS 2016.
Loading gallery...
Video Anonymization
Finally, we demonstrate the versatility of MeDM. For example, MeDM can perform video anonymization out-of-the-box. We leverage the fact that human visual perception exhibits a remarkable sensitivity to human faces while our ability to detect and recognize other objects is not as specialized. We add noise to a video with a strength of 0.5T, which is strong enough to erase the identity while preserving other objects and the background scene, and perform denoising using MeDM to obtain the anonymized video. Text conditioning can also be injected to enable a more targeted identity modification. Celebrity videos from CelebV-HQ.